
AI人声模拟
相遇皆是缘分
可以模拟真人声音,不过需要大量训练模型(请勿乱用)
源码及教程
基本用法
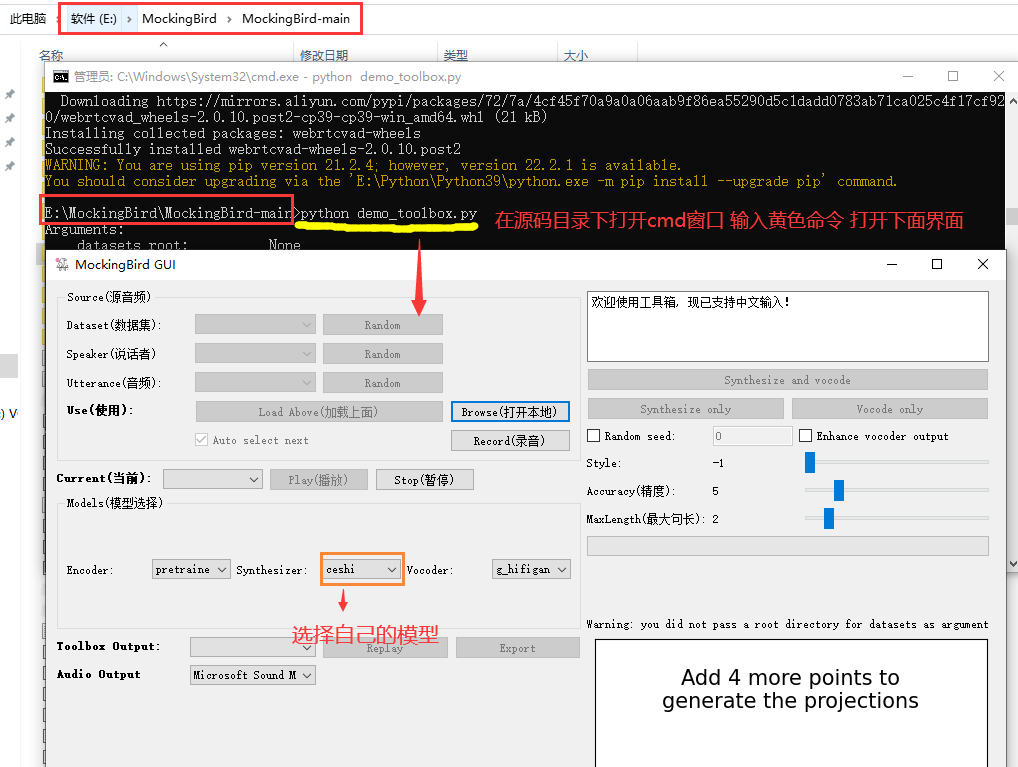
打开界面
1 | python demo_toolbox.py |
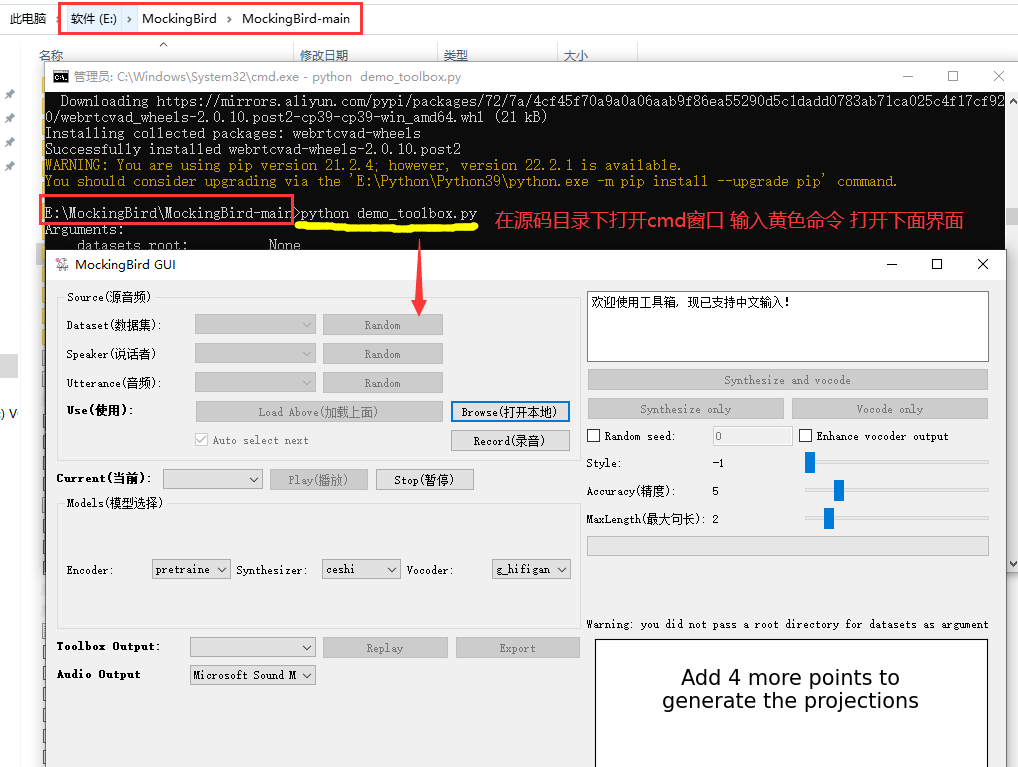
界面功能
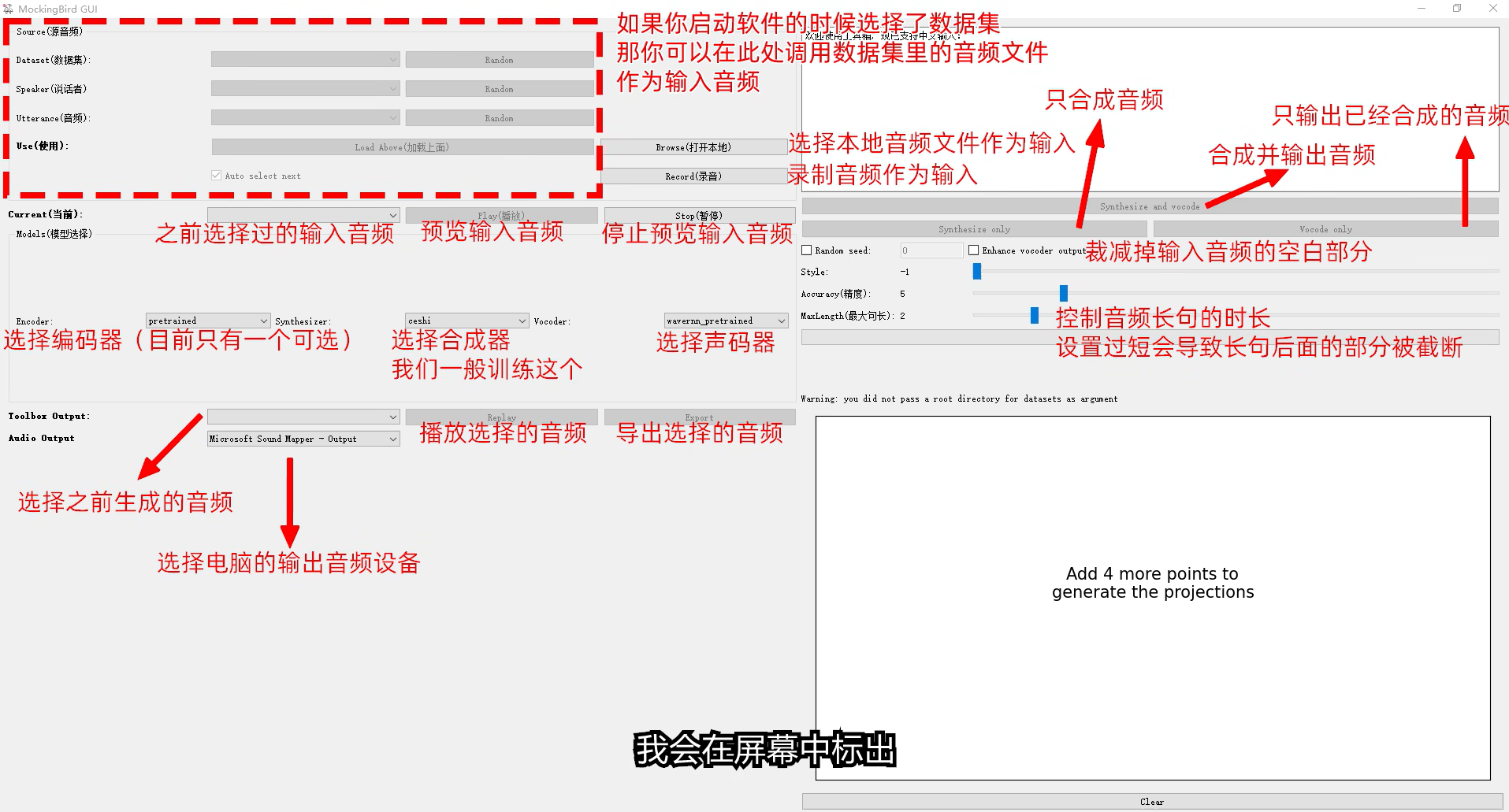
AI 模型制作流程
videosrt(音频识别文字)
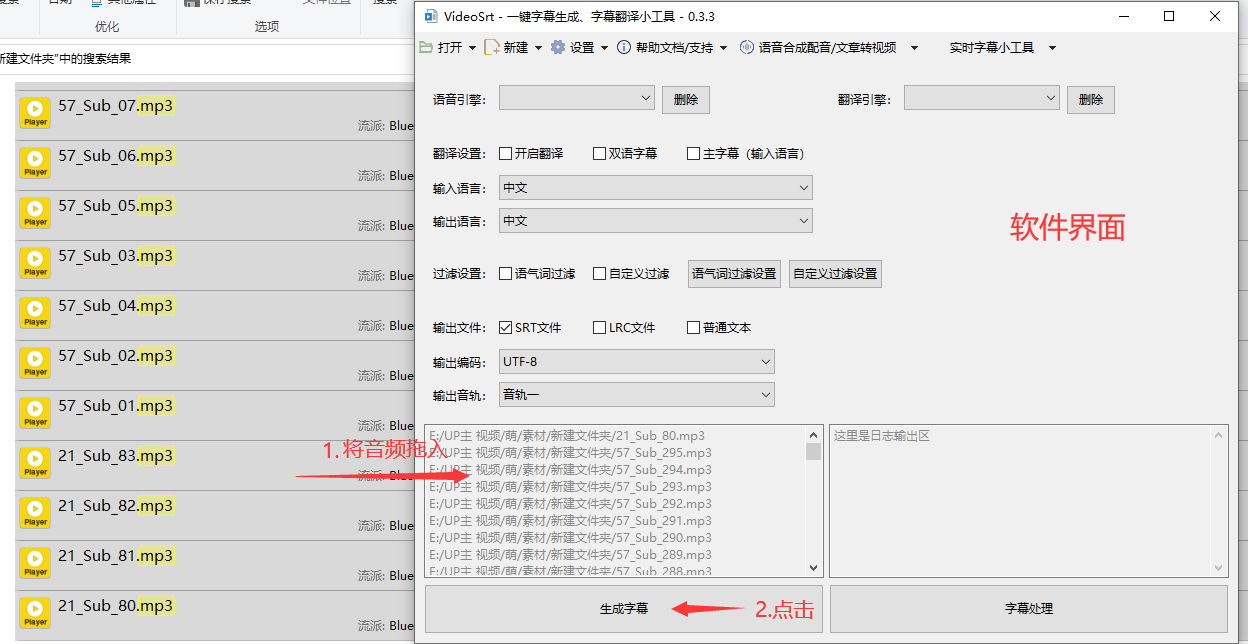
将多个音频识别成文字,并输出到txt文本
- 给所有音频生成文本 格式为 SRT文件 (语音引擎:阿里云 自己配)
2.存放音频和文本
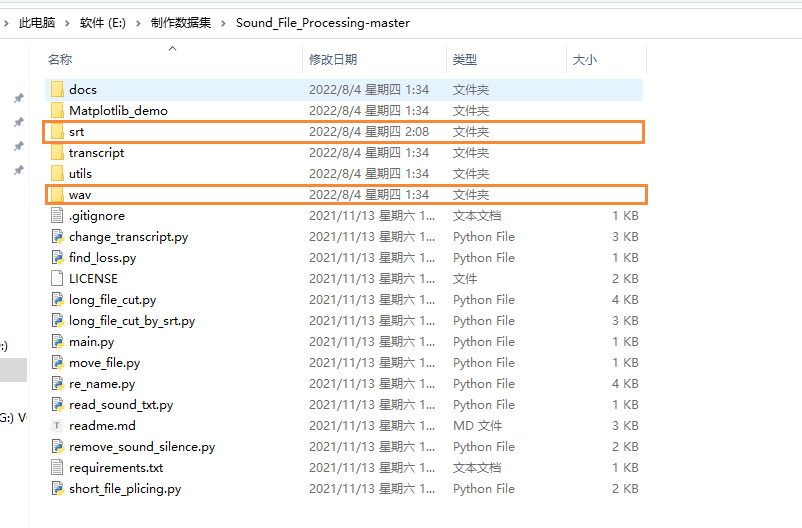
2.1音频
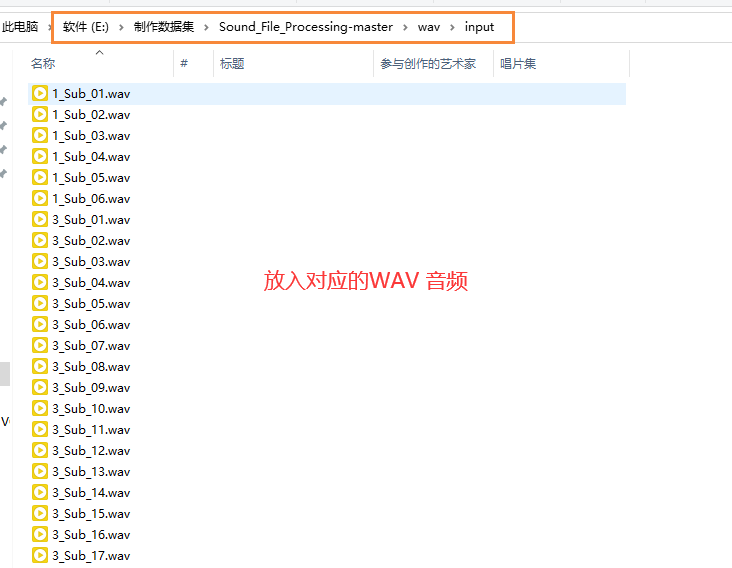
2.2文本
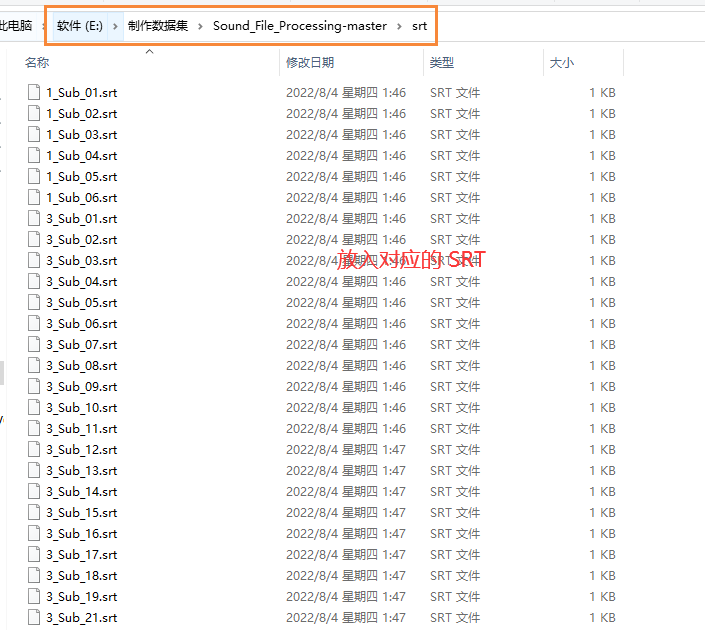
3.生成音频文字
1 | python long_file_cut_by_srt.py |
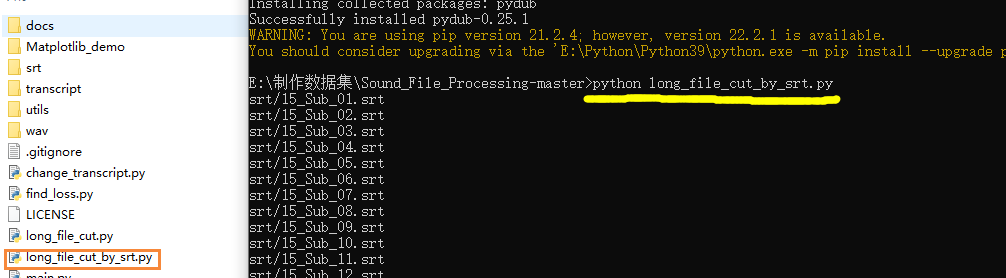
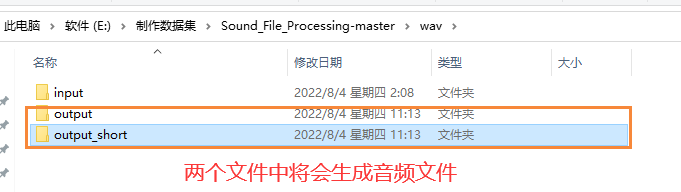
4.听音频校对文本
文本与相应的音频不对就更改,音频不清楚导致文本差错大,可以把该行文本删除,保证几百行没大问题
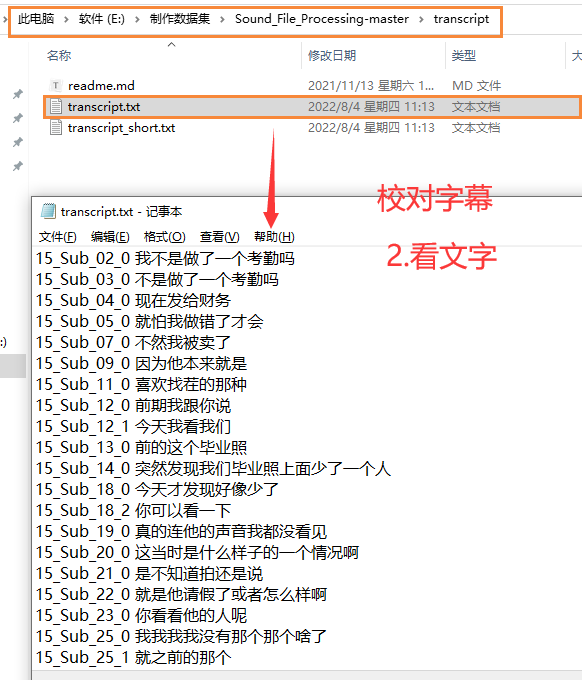
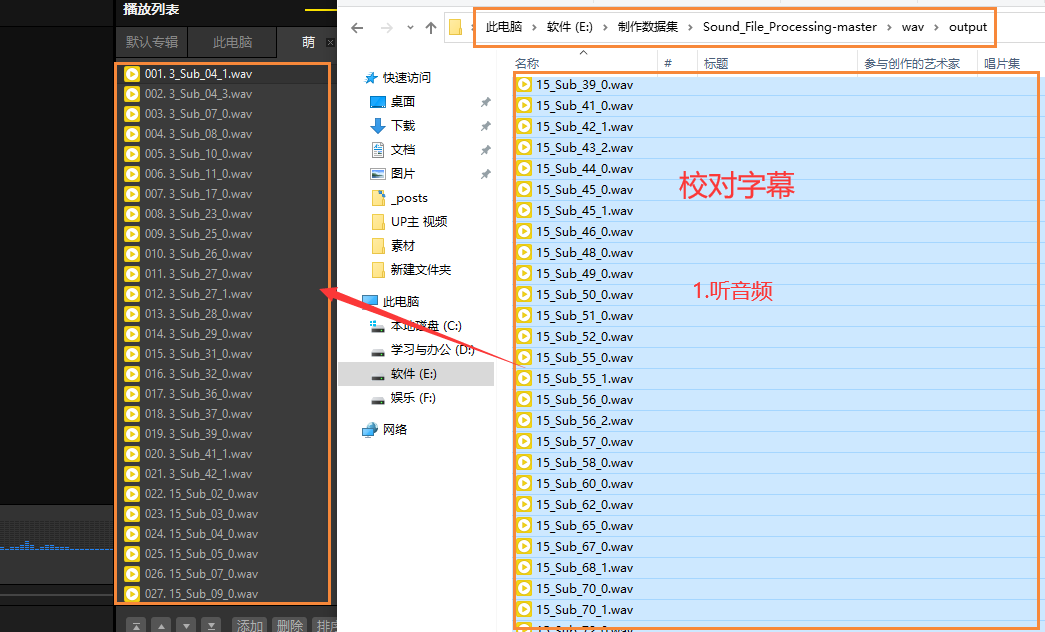
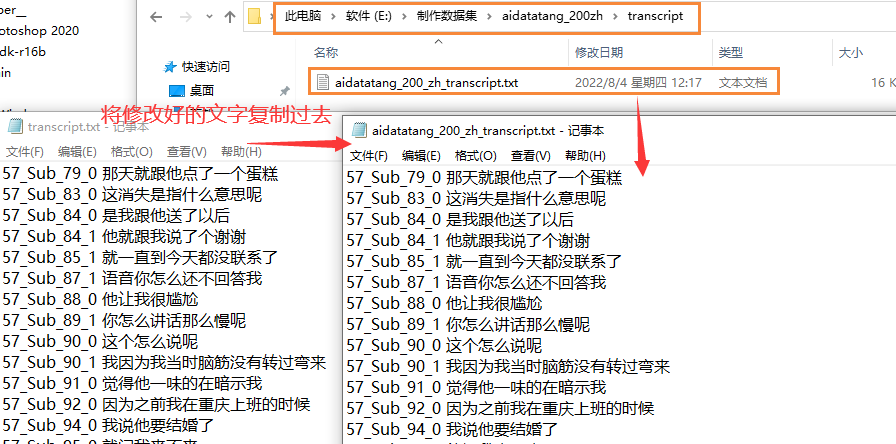
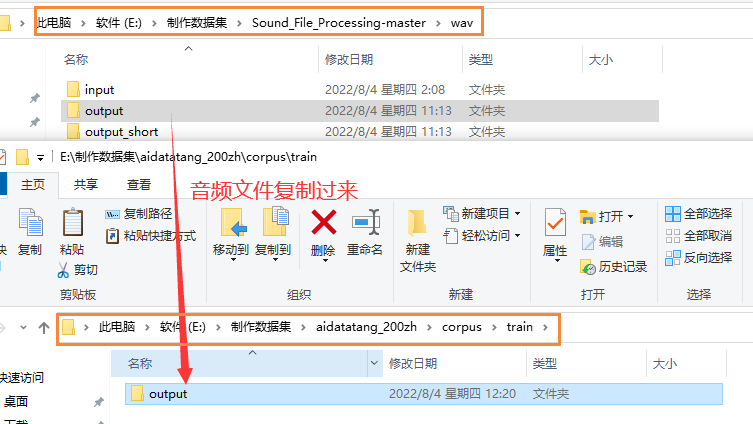
5.校对完毕,移植
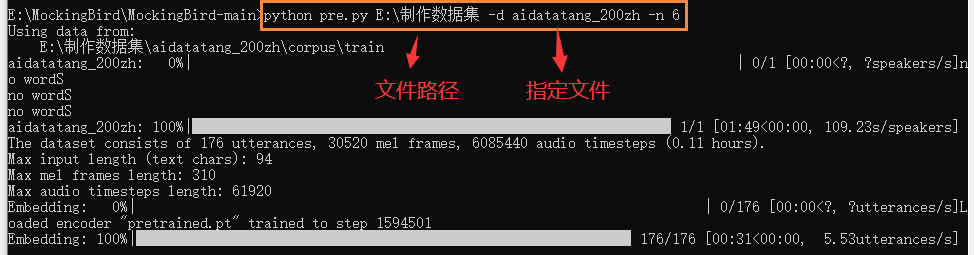
6.生成模型命令
1 | python pre.py <datasets_root> -d {dataset} -n {number} |
1 | python synthesizer_train.py mandarin <datasets_root>/SV2TTS/synthesizer |
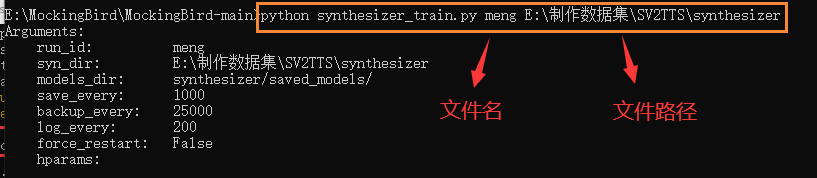
数据小,执行命令几分钟后,ctrl+c 终止
用原作者公开的已有模型,改成自己模型的名称,代替,并再次执行命令,执行几个小时后,查看plots文件是否有音频图,有,证明有效果,运行完数据量太大, 几个小时后,终止即可
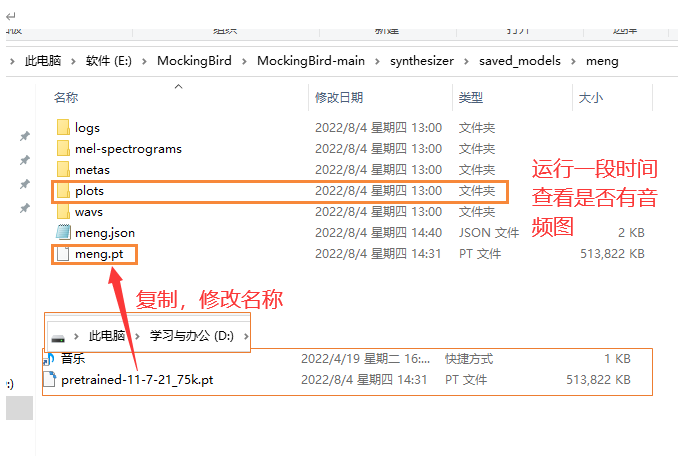
6.将自己的模型放入模型库
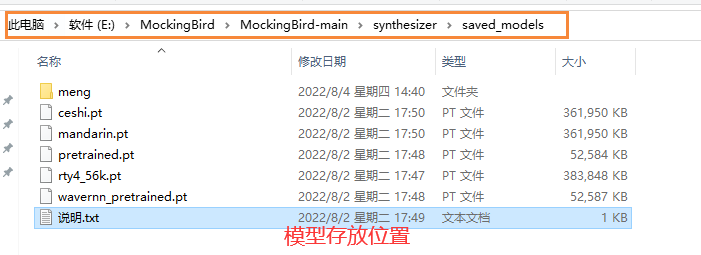
7.运用自己的模型(详细查看 基本用法)
评论